Centralized Logging, Here is why you should use EVK instead of ELK, No logstash anymore !
Centralized logging is very useful when attempting to identify problems with your servers or applications, as it allows you to search through all of your logs in a single place.

Introduction
Centralized logging is very useful when attempting to identify problems with your servers or applications, as it allows you to search through all of your logs in a single place.
It is also useful because it allows you to identify issues that span multiple servers by correlating their logs during a specific time frame.
Generally When a logging system is needed, everyone go for the ELK Stack a collection of three open-source products — Elasticsearch, Logstash, and Kibana — all developed, managed and maintained by Elastic.
As we can see all the logs processing(Filter, Grok, Mutate,…) is done on single place and this can be very painful.
However, for handling more complex pipelines built for handling large amounts of data in production, additional components are likely to be added into your logging architecture, for resiliency (Kafka, RabbitMQ, Redis) and security (Nginx):

This is of course a simplified diagram for the sake of illustration. A full production-grade architecture will consist of multiple Elasticsearch nodes, perhaps multiple Logstash instances, an archiving mechanism, an alerting plugin and a full replication across regions or segments of your data center for high availability. You can read a full description of what it takes to deploy ELK as a production-grade log management and analytics solution in the relevant section below.
The Next Level
Once your applications start to generate huge logs, then you can have several Out Of Memory, the best solution is to Process logs in the client side using the Vector Agent.
In this article we are going to use the EVK Stack which uses Vector instead of Logstash.
- E stands for ElasticSearch: a database used for storing and indexing logs
- V stands for Vector : used for both shipping as well as processing logs
- K stands for Kibana: is a visualization tool (a web interface) that uses Elasticsearch DB to Explore, Visualize, and Share
Following is a diagram explaining the basic concepts of the logging system
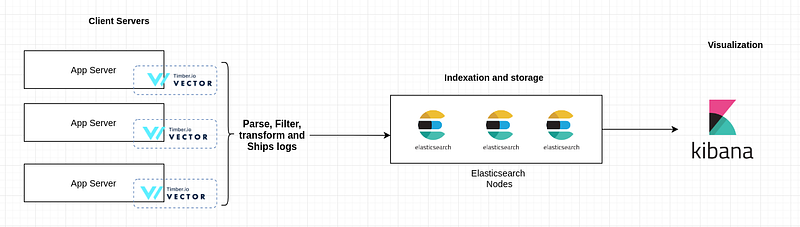
Why Vector ?
Vector is a high-performance observability data router, built in Rust, It makes collecting, transforming, and sending logs, metrics, and events easy.
Memory efficient and fast
Vector is fast and memory-efficient and doesn’t have a runtime and garbage collector.

It decouples data collection & routing from your services, giving you control and data ownership, among many other benefits.



Test cases
The team behind Vector has also invested in a robust test harness that provides a data-driven testing environment.
Here are the test results:
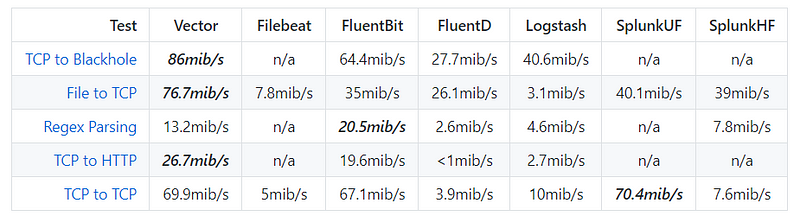
Image source: GitHub
Please check the full tutorial of the implementation of an EVK Stack

